Inferencia rápida de XGBoost, LightGBM y CatBoost en la CPU
Mejora la velocidad de tus cargas de trabajo de inferencia de XGBoost, LightGBM y CatBoost con Intel® oneAPI Data Analytics Library (oneDAL)
A pesar de la reciente popularidad de la IA generativa, utilizar el aumento de gradiente en árboles de decisión sigue siendo el mejor método para tratar con datos tabulares. Ofrece una mayor precisión en comparación con muchas otras técnicas, incluso redes neuronales. Muchas personas utilizan el aumento de gradiente con XGBoost*, LightGBM y CatBoost para resolver diversos problemas del mundo real, realizar investigaciones y competir en competencias de Kaggle. Aunque estos marcos ofrecen un buen rendimiento de manera predeterminada, aún se puede mejorar la velocidad de predicción. Teniendo en cuenta que la predicción es posiblemente la etapa más importante del flujo de trabajo de aprendizaje automático, las mejoras en el rendimiento pueden ser muy beneficiosas.
El siguiente ejemplo muestra cómo convertir tus modelos para obtener predicciones significativamente más rápidas sin pérdida de calidad (Tabla 1).
import daal4py as d4p d4p_model = d4p.mb.convert_model(xgb_model) d4p_prediction = d4p_model.predict(test_data)
Actualizaciones a oneDAL
Han pasado unos años desde nuestro último artículo sobre inferencia acelerada (Mejorando el rendimiento de XGBoost y LightGBM en inferencia), así que pensamos que era hora de ofrecer una actualización sobre los cambios y mejoras realizados desde entonces:
- API simplificada y alineación con los marcos de aumento de gradiente
- Compatibilidad con modelos de CatBoost
- Compatibilidad con valores faltantes
- Mejoras en el rendimiento
API simplificada y alineación con los marcos de aumento de gradiente
Ahora solo tienes los métodos convert_model() y predict(). Puedes integrar esto fácilmente en tu código existente con cambios mínimos:
También puedes convertir el modelo entrenado a daal4py:
XGBoost:
d4p_model = d4p.mb.convert_model(xgb_model)
LightGBM:
d4p_model = d4p.mb.convert_model(lgb_model)
CatBoost:
d4p_model = d4p.mb.convert_model(cb_model)
También se admiten estimadores en el estilo de scikit-learn*:
from daal4py.sklearn.ensemble import GBTDAALRegressor reg = xgb.XGBRegressor() reg.fit(X, y) d4p_predt = GBTDAALRegressor.convert_model(reg).predict(X)
La API actualizada te permite usar modelos de XGBoost, LightGBM y CatBoost en un solo lugar. También puedes utilizar el mismo método predict() tanto para clasificación como para predicción, igual que en los marcos principales. Puedes obtener más información en la documentación.
Compatibilidad con modelos de CatBoost
Agregar soporte para modelos de CatBoost en daal4py mejora significativamente la versatilidad y eficiencia de la biblioteca en la manipulación de tareas de aumento de gradiente. CatBoost, abreviatura de aumento categórico, es conocido por su velocidad y rendimiento excepcionales, y con la aceleración de daal4py, puedes ir aún más rápido. (Nota: No se admiten características categóricas para inferencia). Con esta adición, daal4py abarca tres de los marcos de aumento de gradiente más populares.
Compatibilidad con valores faltantes
Los valores faltantes son comunes en conjuntos de datos del mundo real. Esto puede ocurrir por diversas razones, como errores humanos, problemas en la recopilación de datos o incluso las limitaciones naturales de un mecanismo de observación. Ignorar o manejar incorrectamente los valores faltantes puede llevar a análisis sesgados o sesgados, lo que en última instancia degrada el rendimiento de los modelos de aprendizaje automático.
El soporte para valores faltantes se introduce ahora en la versión 2023.2 de daal4py. Puedes utilizar modelos entrenados con datos que contengan valores faltantes y utilizar datos con valores faltantes en la inferencia. Esto proporciona predicciones más precisas y robustas al mismo tiempo que agiliza el proceso de preparación de datos para científicos de datos e ingenieros.
Mejoras en el rendimiento
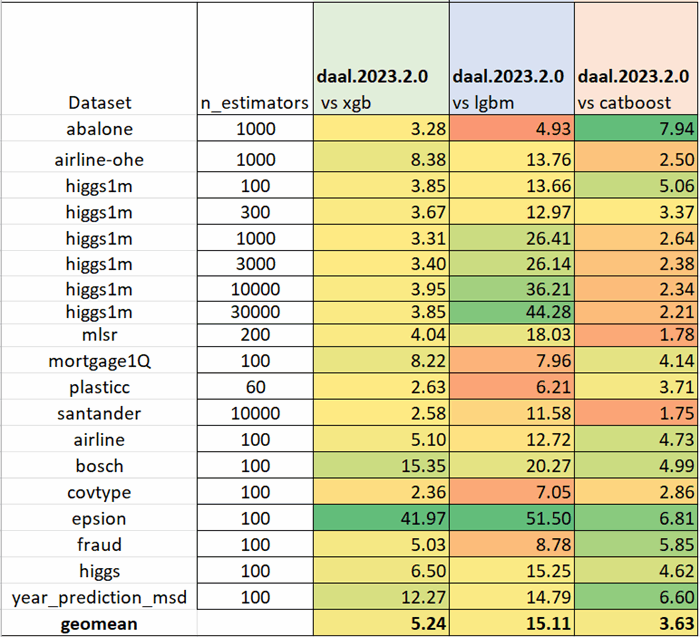
Se han agregado muchas optimizaciones adicionales a oneDAL desde nuestras últimas comparaciones de rendimiento (Tabla 2).
Todas las pruebas se realizaron utilizando scikit-learn_bench ejecutado en una instancia AWS* EC2 c6i.12xlarge (que contiene un Intel® Xeon® Platinum 8375C con 24 núcleos) con el siguiente software: Python* 3.11, XGBoost 1.7.4, LightGBM 3.3.5, CatBoost 1.2 y daal4py 2023.2.1.
Sus contribuciones son bienvenidas para ampliar la cobertura de nuevos casos y otras mejoras.
Cómo obtener daal4py
daal4py es la interfaz de Python de la biblioteca oneDAL y está disponible en los canales principales de PyPi, conda-forge y conda. Este es un proyecto completamente de código abierto y damos la bienvenida a cualquier problema, solicitud o contribución a través del repositorio de GitHub. Para instalar la biblioteca desde PyPi, simplemente ejecute:
pip install daal4py
O la variante conda-forge:
conda install -c conda-forge daal4py --override-channels
Estos resultados muestran que al hacer un cambio simple en su código, puede acelerar significativamente sus tareas de análisis de datos de impulso de gradiente en su hardware Intel® actual. Estas mejoras en el rendimiento pueden reducir los costos de computación y ayudarlo a obtener resultados más rápidamente, todo sin comprometer la calidad.









Leave a Reply